On Conversation - Making a Simple Chatbot in Python
tl;dr We will start by building a chatbot in Python 3 in order to trick the user into thinking that the bot has actual understanding of the conversation. We want to imitate a Rogerian psychotherapist, so we will answer whatever the user inputs with a question. Git clone the final version of my code here or, if you are feeling even lazier, copy it from this gist.
As of last year, thanks to my internship at the Computer Vision Center and the work I did there using Reinforcement Learning, I have become extremely interested in both the current state and applications of AI, as well as its origins. Without much reservation, there was an area I did not hold particularly dear: that of Natural Language Processing, or NLP. I believe this was due to what was presented to me as being the application of NLP: chatbots, in particular, chatbots for companies (I will admit another popular area in NLP is that of predictive text keyboards, which most of the times get hilarious results and I wish to experiment with this later on).
I have used chatbots in the past, and they have never been engaging or, in the majority of the cases, even useful in answering my questions or solving my problems; there was always a need for a human representative for help. In retrospective, I should immediately note that this was due to bias: chatbots are key in answering routine questions (and saving company money), of which I never ask. Indeed, I prefer to find the answer for myself (or by other user’s questions), and if no answer satisfies my need, then I would contact the company. In the cases my questions arrived a chatbot, it would always end with a non-answer or waiting time for a customer representative to get back to me. Thus, perhaps I was being too harsh on both NLP, but especially chatbots.
There were other key turning points that made me look at chatbots in a different light. One of these was reading Greg Brockman’s path to AI. Was I truly missing something by not looking at chatbots in a more positive way? After all, language is one of the key pillars in society, indeed in intelligence. Should I not then explore them further?
Perhaps chatbots had far more to offer than what I had initially realized or was willing to give credit for. This was reinforced when, whilst attending 2018’s State of Latino Entrepeneurship Forum, I met Conchita Franco Serri, Founder and CEO of Caroami. What Caroami plans to do (as it hasn’t yet to launched), is to resolve conflicts between two parties via a mediator, the chatbot. They will start with small scale conflicts, like disputes between roomates, or between couples, and then scale as time progresses. Perhaps they are overselling what their bot can do now, but it has great potential. Indeed, chatbots, like any other machine learning paradigm, will get better with more data.
This was further cemented when, whilst completing Coursera’s Deep Learning Specialization, Prof. Andrew Ng showed us a new chatbot for mental health: Woebot. Whilst not a complete replacement for therapists, Woebot offers a far more powerful use for chatbots than I had ever seen before, and I loved it (and have even started to use it). After that, I found spaCy, which offer industrial-strength NLP in different languages, and I basically just started to play with it. From analyzing and visualizing novel snippets, to comparing sentences via word vectors (more on that on a later blog post).
By this point I have decided to build my own chatbot, and this is where we are now. Thus, I will write a bit of what I have learned (which is also a bit), and then we will proceed to both make our chatbot, as well as to gradually improve it, using more advanced tools like spaCy and TensorFlow.
A bit of history
Since we are trying to start making our own chatbots, it is natural for us to look back in time and read about the first chatbot ever made. This was ELIZA, created by Joseph Weizenbaum from 1964 to 1966 at the MIT Artificial Intelligence Laboratory. ELIZA was born with the capacity to gain better language abilities, as its name implies.
An extract of a typical conversation between a user and the original ELIZA can be found in the original paper by Weizenbaum and is shown next (‘?’ was a forbidden character, due to the implementation in the MAC system, hence no questions):
Men are all alike.
IN WHAT WAY
They're always bugging us about something or other.
CAN YOU THINK OF A SPECIFIC EXAMPLE
Well, my boyfriend made me come here.
YOUR BOYFRIEND MADE YOU COME HERE
He says I'm depressed much of the time.
I AM SORRY TO HEAR YOU ARE DEPRESSED
with the capitalized lines being the machine responses. The summary of the algorithm is as follows:
- The standrad input (input by the user) is inspected in search of a keyword.
- If found, the input is transformed according to a rule associated with said keyword, else, a content-free remark or an earlier transformation is retrieved.
- The text is then transformed (e.g., from second person to first person) and is printed out to the standard output.
- Since the script is taken as data, then this method is not restricted to one language. Indeed, you can find a working version of ELIZA in Spanish here.
In a way, Weizenbaum was trying to show how superficial was the communication between man and machine. Indeed, while the amount of rules that ELIZA has for each keyword is vast (besides other parts of the algorithm), ELIZA did not actually possess understanding of the input. Still, some users (including Weizenbaum’s secretary) found ELIZA to have a personality, even becoming emotionally attached. Perhaps this was due to the shortness of the sessions where the users interacted with ELIZA, but this still is quite interesting to note.
This clashed with Weizenbaum. According to him, we should never allow computers to make any decisions, as they lack compassion and wisdom, purely human emotions. Humans have judgement, which in turn allows us to compare apples with oranges, and a relatively short algorithm and/or mathematical expression translated to code would not be able to do this. This is even more apparent in the following quote (from an excerpt found online of his book Computer Power and Human Reason):
Just because so much of a computer-science curriculum is concerned with the craft of computation, it is perhaps easy for the teacher of computer science to fall into the habit of merely training. But, were he to do that, he would surely diminish himself and his profession. He would also detach himself from the rest of the intellectual and moral life of the university.
The perils of computation is that of robbing us of our humanity, and it has been a pressing issue lately as AI has been steadily advancing. Hopefully, we will be ready when the time comes.
Let’s get started then.
Building ELIZA
The chatbot we will build will be greatly influenced by the following examples found online:
- Noah Moroze’s simpleChatBot
- Jezz Higgin’s recreation of ELIZA
- DataCamp’s course on building chatbots in Python given by Alan Nichol, co-founder and CTO of Rasa.
The latter will set the tone and direction we will take, as it helped me realize how to slowly grow and scale this endeavor. We will develop our code for Python 3.5, but it can be easily translated into any other version of Python. So, in order for the user and chatbot to engage in a conversation, we have the following template (to be filled) by the algorithm we will develop later on:
user_template = "USER: {0}"
bot_template = "ELIZA: {0}"
I prefer this template to the original by Weizenbaum, as this will make it easier for the user to understand which line is done by the user and which by ELIZA. As a first step, ELIZA will simply repeat back the message the user inputs:
def respond(message):
# Concatenate the user's message to the end of a standard bot response
bot_message = "I can hear you! You said: " + message
return bot_message
For the bot to receive the message sent by the user, we must define another function, send_message(), which will process the message that the user inputs, whilst printing it and the ELIZA’s response:
def send_message(message):
# Print user_template including user_message
print(user_template.format(message))
# Get ELIZA's response to the message:
response = respond(message)
# Print the bot template including ELIZA's response:
print(bot_template.format(response))
For example, we have the following input and output:
>>> send_message("Hello there!")
"USER: Hello there!"
"ELIZA: I can hear you! You said: Hello there!"
>>> send_message("So I did. How are you?")
"USER: So I did. How are you?"
"ELIZA: I can hear you! You said: So I did. How are you?"
>>> send_message("wtf")
How to talk to a Bot 101
At this point, any normal human being would end the conversation, and rightly so. While the Echo Effect might have shown some promise, the extreme case we are dealing with now of repeating back everything is detrimental at best; the bot can pretend to be another user only so far.
The current version of ELIZA lacks everything by which we judge a conversation with another human, perhaps even moreso a machine, as being meaningful or memorable, even less having the personality that Weizenbaum’s secretary described that the original ELIZA had. Personality is essential to any chatbot, indeed to any human! This is subconciously expected by the user: if it does not meet our expectations, then we shy away from it (like I used to do), and this is why I particularly despise call centers and the scripts that they demand their customer representatives/salesmen to not deviate from.

Hi! This is the T-1000...I mean, Jenny, I will be your customer representative today!
As such, we can add a responses dictionary, with the keys being the common questions asked by the user, and the values being the answer we will have ELIZA answer. Starting slowly, this means:
responses = {"what's your name?": "My name is ELIZA",
"what's the weather today?": "it's rainy!",
"default": "default message"}
And we would modify our respond() function accordingly:
def respond(message):
# We check if the message has a pre-defined response
if message in responses:
# If it does, then we return the matching response
bot_message = responses[message]
else:
# Otherwise, return the default message
bot_message = responses["default"]
return bot_message
Thus:
>>> send_message("what's your name?")
"USER: what's your name?"
"ELIZA: My name is ELIZA"
>>> send_message("what's the weather today?")
"USER: what's the weather today?"
"ELIZA: it's rainy!"
>>> send_message("what's the meaning of life?")
"USER: what's the meaning of life?"
"ELIZA: default message"
>>> send_message("how insightful!")
Perhaps this subsection title promised too much, but we can do better.
Adding Complexity
We note that this solution has a weakness, in that if the user does not input exactly any of the keys in the responses dictionary, then we wouldn’t get a response. That’s why we introduced the "default" key with a "default message", akin to what Google Assistant does when the user asks something it cannot do, or when it doesn’t understand the command. This default message will be later edited to say something more helpful for the user.
Humans do not have a constant dictionary of answers that we resort to when asked a question, or when engaging in a conversation (we even deviate from things we think we will say beforehand). Thus, while certainly an improvement, this version of ELIZA still has potential for improvement, for more complexity in its interactions.
Two ways in which we can do this are as follow:
- Having placeholders for variables, such as the weather, mood, or even name of our bot.
- Add more than one way to answer a question, i.e., variety in dialogue.
For the former, it is sufficient to declare variables that can be updated regularly and use them with the standard str.format() method. For the latter, we will add multiple answers to each question using a list and choose randomly from them. For example, when the user asks about the weather, our responses dictionary and new variable weather_today are:
weather_today = "rainy"
responses = {"what's the weather today?": ["it's {0} today".format(weather_today),
"the local weather is {0}".format(weather_today),
"it seems it will be {0} today".format(weather_today)],
"default": ["default message"]}
So, we will make ELIZA to answer the questions by randomly selecting from the list of answers using the random module and modifying our respond() function yet again:
import random
def respond(message):
# We check if the message has a pre-defined response
if message in responses:
# We declare bot_message, which will be a random matching response to the message
bot_message = random.choice(responses[message])
else:
# We return a random matching default response, which can be more than one
bot_message = random.choice(responses["default"])
return bot_message
We then get:
>>> send_message("what's the weather today?")
"USER: what's the weather today?"
"ELIZA: the local weather is rainy"
>>> send_message("what's the weather today?")
"USER: what's the weather today?"
"ELIZA: it's rainy today"
>>> send_message("will it rain today?")
"USER: will it rain today?"
"ELIZA: default message"
10/10, would consult again.
Questions vs. Statements
To keep the conversation going, we can also have ELIZA ask questions to our users, regardless of what the user sends as a message. Concretely, these may not even be direct questions regarding the user input, regarding instead on whether the user’s message was a question or a statement. Thus, we can instead have our responses dictionary to be the following:
responses = {"question": ["I don't know T_T",
"you tell me"],
"statement": ["tell me more!",
"why do you think that?"
"how long have you felt this way?",
"I find that extremely interesting",
"tell me more!",
"can you back that up?",
"oh wow!",
":^)"]}
The easiest way to know if the user is asking a question is whether or not there’s a question mark at the end of the message input. We reflect this in our respond() function:
def respond(message):
# We check if there is a question mark
if message.endswith("?"):
# We return one of the 'question' responses
bot_message = random.choice(responses["question"])
else:
# Otherwise, return one of the 'statement' responses
bot_message = random.choice(responses["statement"])
return bot_message
A typical example of this would be:
>>> send_message("what's today's weather?")
"USER: what's today's weather?"
"ELIZA: you tell me!"
>>> send_message("I love you ELIZA!")
"USER: I love you ELIZA!"
"ELIZA: how long have you felt this way?"
Regular Expressions (regex) and Grammar
Regular expressions, or regex, are a sequence of characters that we will use to match messages with search patterns, to extract key phrases, and even to transform the sentence from the second to first person, for example. Thus, we will need a set of rules (patterns) for matching the messages by the user, and we will use these in conjunction with the re module from Python to use the regular expressions.
Covering the basics, this is how we will use the re module:
>>> import re
>>> pattern = "if (.*)"
>>> message = "what would happen if you ate the Takis?"
>>> match = re.search(pattern, message)
>>> match.group(0) # Will return the entire match
"if you ate the Takis?"
>>> match.group(1) # Will return only the parenthesized subgroup
"you ate the Takis?"
Thus, our goal appears: we will find the subject that the user is asking about in the message string, extract it, and if necessary restructure it gramatically such that the answer that ELIZA gives back makes sense. For illustration, we can use the re.sub method by defining a new function, swap_pronouns(), like so:
import re
def swap_pronouns(phrase):
if "I" in phrase:
return re.sub("I", "you", phrase)
if "my" in phrase:
return re.sub("my", "your", phrase)
else:
return phrase
And then:
>>> swap_pronouns("This is my book.")
"This is your book."
>>> swap_pronouns("I walk my dog.")
"You walk your dog."
The huge advantage we have is that we are using the English language, which can be thus reduced to simple rules of switching pronouns (albeit many), which would not be a small task in other languages. Let us then continue on building on ELIZA’s complexity.
Key phrases extraction and More Grammar
The true cleverness of the original ELIZA relied on the parrot-esque design of its algorithms. Indeed, repeating back parts of what has just been discussed helps in deceiving our user, making him or her think that the chatbot has true understanding of the conversation, without adding complexity in our code.
Continuing where we left off in the last section, we define a dictionary of rules which we will use to match different patterns in the user’s message:
rules = {"I want (.*)": ["What would it mean if you got {0}?",
"Why do you want {0}?",
"What's stopping you from getting {0}?"],
"do you remember (.*)": ["Did you think I would forget {0}?",
"Why haven't you been able to forget {0}?",
"What about {0}?",
"Yes ...and?"],
"do you think (.*)": ["if {0}? Absolutely.",
"No way Jose"],
"if (.*)": ["Do you really think that it's likely that {0}?",
"Do you wish that {0}?",
"What do you think about {0}?"]}
Now, we define the function match_rule() with which we will match a rule in the rules dictionary to the user’s message:
def match_rule(rules, message):
# We have some default message and phrase to return
response, phrase = "default", None
# We iterate over the rules dictionary
for pattern, responses in rules.items():
# Create a match object with re.search()
match = re.search(pattern, message)
if match is not None:
# Choose a random response
response = random.choice(responses)
# If there is a placeholder in the response, we must fill it
if "{0}" in response:
# Our phrase will be the parenthesized subgroup
phrase = match.group(1)
# Return both the response and phrase
return response, phrase
For example:
>>> print(match_rule(rules=rules, message="do you remember your last birthday?"))
("Why haven't you been able to forget {0}", 'your last birthday')
We are almost done, we just need to change from second to first person, and we will be ready to integrate this into what we have so far of our algorithm. For this, we define yet again another function that will help us in changing the pronouns (note that we could also do this with a dictionary):
def replace_pronouns(message):
# We lowercase our message in order to avoid any ambiguity
# as well as remove the final punctuations
message = message.lower().strip('.!?')
# We will replace "i" with "you", "you" with "me", etc.
if "am" in message:
return re.sub("am", "are", message)
if "are" in message:
return re.sub("are", "am", message)
if "i " in message:
return re.sub("i ", "you ", message)
if ("i'd" or "i would") in message:
return re.sub("i'd|i would", "you would", message)
if ("i've" or "i have") in message:
return re.sub("i've|i have", "you have", message)
if ("i'll" or "i will" or "i shall") in message:
return re.sub("i'll|i will|i shall", "you will", message)
if "me" in message:
return re.sub("me", "you", message)
if "my" in message:
return re.sub("my", "your", message)
if "was" in message:
return re.sub("was", "were", message)
if "yours" in message:
return re.sub("yours", "mine", message)
if "your" in message:
return re.sub("your", "my", message)
if "you" in message:
return re.sub("you", "I", message)
if ("you'll" or "you will") in message:
return re.sub("you'll|you will", "you", message)
if ("you've" or "you have") in message:
return re.sub("you've|you have", "I have", message)
# We return either the changed message, or the original message
return message
We test it like so:
>>> replace_pronouns("my car is over there")
'your car is over there'
>>> replace_pronouns("when you went to the lake")
'when I went to the lake'
Some replacements won’t make sense, grammatically speaking. This is obvious that would happen, since we are basically hard-coding all the responses that ELIZA will reply with. However, as a basic first step, it serves our purpose, and we then proceed with our final step.

All my base are belong to us.
Putting it all together
In conclusion, using the functions match_rule(), send_message(), and replace_pronouns(), as well as the rules dictionary, we integrate them into a final redefinition of respond() like so:
def respond(message):
# We call match_rule
response, phrase = match_rule(rules, message)
# If there is a placeholder in our response
if '{0}' in response:
# Replace the pronouns
phrase = replace_pronouns(phrase)
# Insert the phrase in the response
response = response.format(phrase)
return response
Thus, we can send some simple messages and see how ELIZA responds:
>>> send_message("do you remember your last birthday?")
"USER: do you remember your last birthday?"
"ELIZA: What about my last birthday"
>>> send_message("I want a robot friend")
"USER: I want a robot friend"
"ELIZA: Why do you want a robot friend"
>>> send_message("do you think humans should be worried about AI")
"USER: do you think humans should be worried about AI"
"ELIZA: if humans should be worried about ai? Absolutely."

I knew it!
Adding more rules, and changing our code a bit in order for it to look nicer on the output (such as removing the 'USER: {0}' template and including the 'ELIZA : {0}' template in the send_message() function), our final code is as follows:
After git clonging/downloading the file from my repository (or just copy and paste from here), this can be easily run on the command shell as python ELIZA.py. You should see something like this:
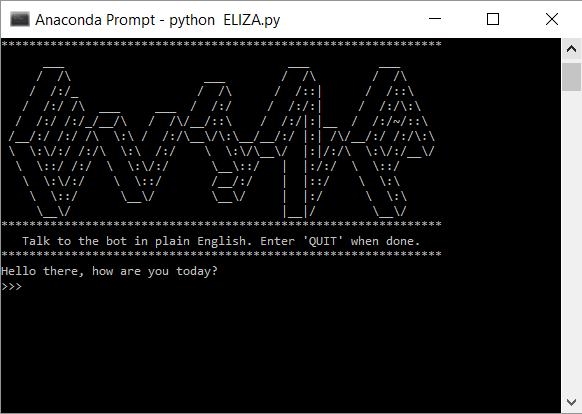
Success!
Hope you enjoyed this as much as I did, have fun chatting with ELIZA and see you next time!